【C++】thread|mutex|atomic|condition_variable

本篇博客,让我们来认识一下C++中的线程操作
所用编译器:vs2019
阅读本文前,建议先了解线程的概念 👉 线程概念
1.基本介绍
在不同的操作系统,windows、linux、mac上,都会对多线程操作提供自己的系统调用接口
为什么C++需要封装一个线程?直接用系统的接口不好吗?
在Linux文件博客中,已经谈过了这一点:对于C++、python、java这些跨平台的语言来说,如果直接用系统的接口,是可以实现对应操作的。但是,这样会导致代码只能在某一个特定平台,甚至是某一个版本的特定操作系统上才能正常运行,直接与跨平台的特性相违背。
解决的办法呢,就是对系统的接口套一个语言级别的软件层,封装系统的接口。并用条件编译的方式来识别不同的操作系统,已调用不同操作系统的系统接口,以实现跨平台性
2.thread类
https://legacy.cplusplus.com/reference/thread/thread/thread/
2.1 构造/赋值
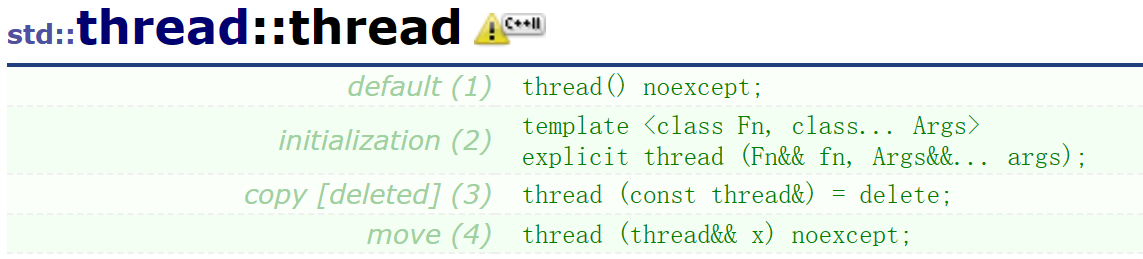
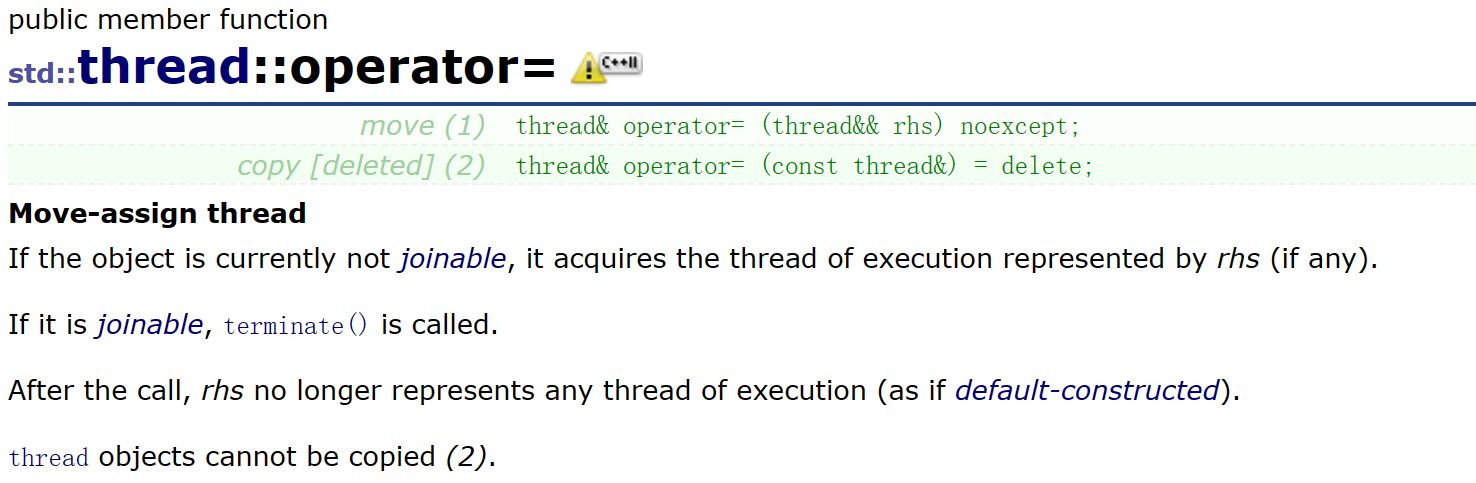
线程是不允许拷贝构造和赋值重载的,但是其支持右值引用的重载(主要是为了匿名对象构造)也支持空构造
右值:无法进行取地址的变量
2.2 get_id
对于线程而言,比较重要的就是这个id号了,其用于标识线程的唯一性

2.3 join/detach
创建好了一个线程,我们需要进行join等待或者detach分离
- 如果主线程不需要获取子进程执行的结果,可以直接执行detach
- 如果需要等待子线程执行,则执行join
为什么会产生这两个分歧呢?是因为join等待是有一定消耗的。如果我们不关心线程执行的返回值,应该采用detach尽量减小消耗
2.4 使用示例
相比于Linux系统提供的pthread接口,C++的使用方法更加直接
#include <iostream>
#include <thread>
using namespace std;void Add(int a, int b)
{cout << a + b << endl;;
}
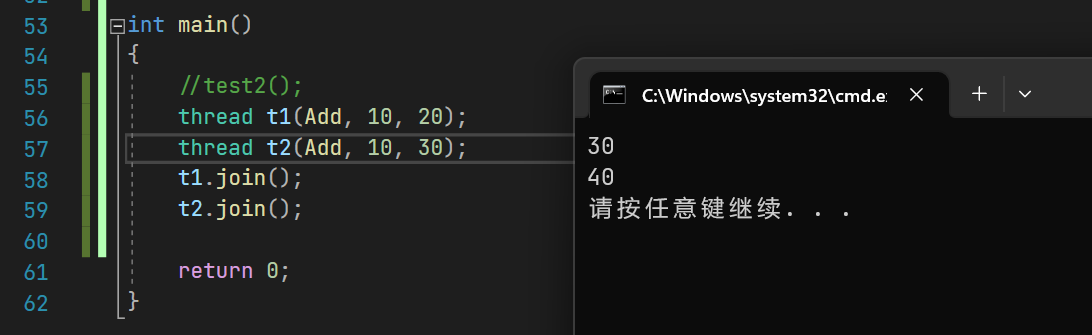
int main()
{thread t1(Add, 10, 20);thread t2(Add, 10, 30);t1.join();t2.join();return 0;
}
2.5 空构造和移动赋值
如果我们只是定义了一个t1,没有直接调用构造函数指定其要运行的函数(其实是调用了空构造)那么要怎么给这个线程指定函数呢?
thread t3;//调用了空构造
别忘了,虽然线程不支持拷贝构造,但他有移动赋值!
thread& operator= (thread&& rhs) noexcept;
我们要做的,就是采用匿名对象的方式,赋值给t3
thread t3;
t3 = thread(Add, 20, 30);
t3.join();

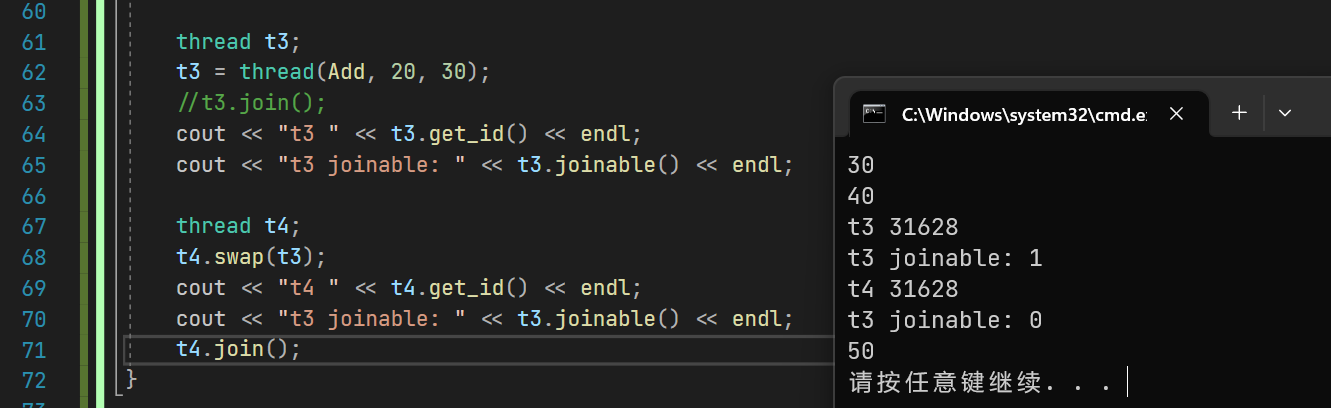
2.6 joinable
bool joinable() const noexcept;
这个函数的作用是标识一个线程是否还能进行join;下面几种情况,线程不能被join
- 只调用了空构造(都没有指定需要运行的函数怎么join等待?)
- 被move了(move会将对象变成将亡值,也就是右值)
- 该对象已经调用过join或者detach
如果是在多层函数中调用的线程,那可能join之前就可以判断一下当前对象是否还能join
2.7 swap/move
void swap (thread& x) noexcept;
该成员函数的作用是将另外一个线程切换给当前线程
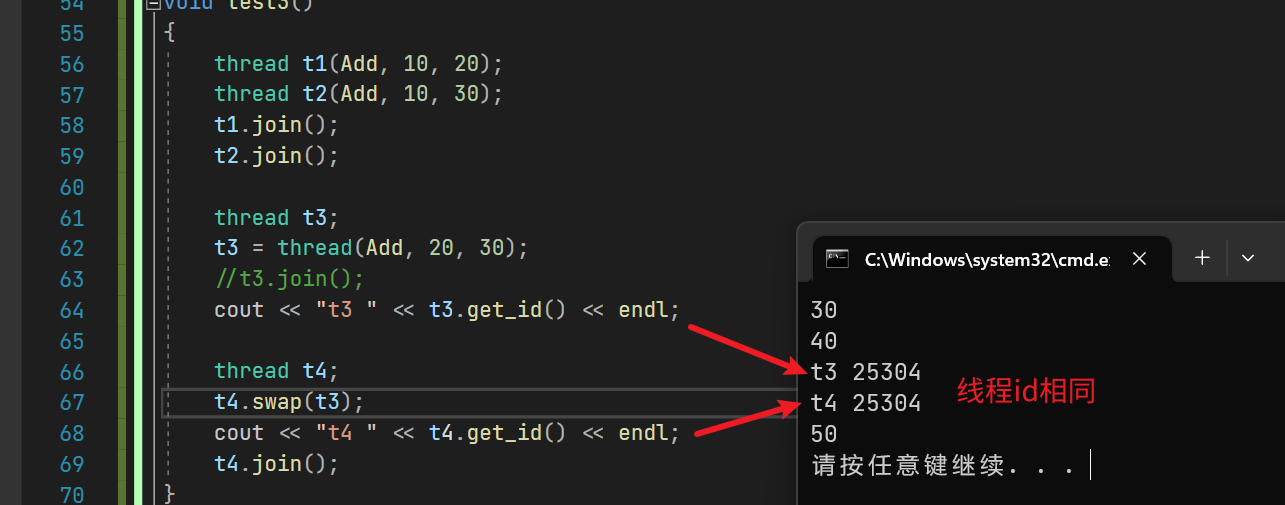
其本质就是一个move移动赋值
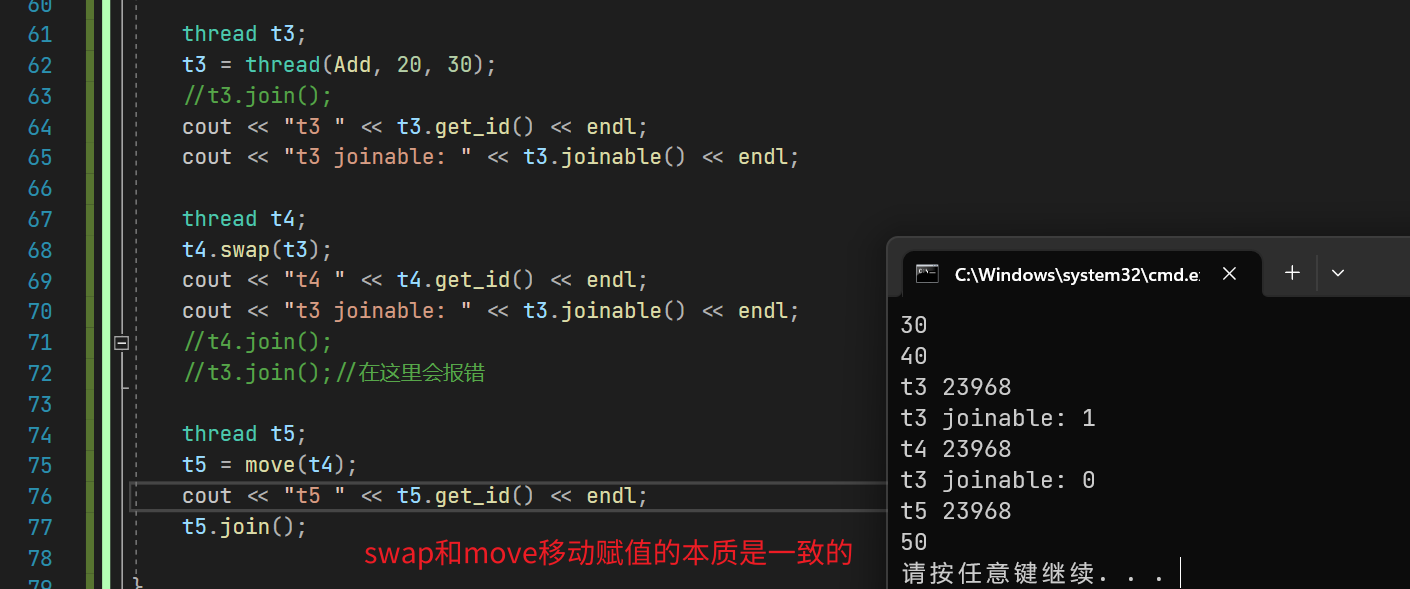
被移动后的线程t3不再joinable,不会运行,也不能被join或detach
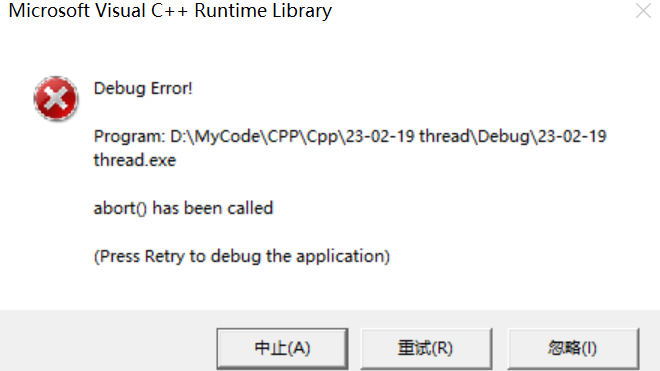
强行join会报错
2.8 linux下编译
由于std是对系统接口进行的封装\\
所以在linux下编译带c++线程库的代码时,需要带上pthread库的选项
g++ test.cpp -o test -std=c++11 -lpthread
3.std::ref
这里有一个特殊的函数ref,要想知道其作用,我们需要先看下面这个场景
3.1 引用传参
#define _CRT_SECURE_NO_WARNINGS 1
//#include <stdio.h>
#include <iostream>
#include <thread>
#include <functional>
using namespace std;void Print(int n,int& a)
{for (int i = 0; i < n; i++){cout << this_thread::get_id() << " " << a++ << endl;}
}int main()
{int count = 0;thread t1(Print,10, count);thread t2(Print,10, count);t1.join();t2.join();cout << "main: " << count << endl;return 0;
}
在这个场景中,我想达到的目标是让t1和t2两个线程帮我们对count进行++,最终在main里面打印结果;可编译会发现报错,不给我们这样写
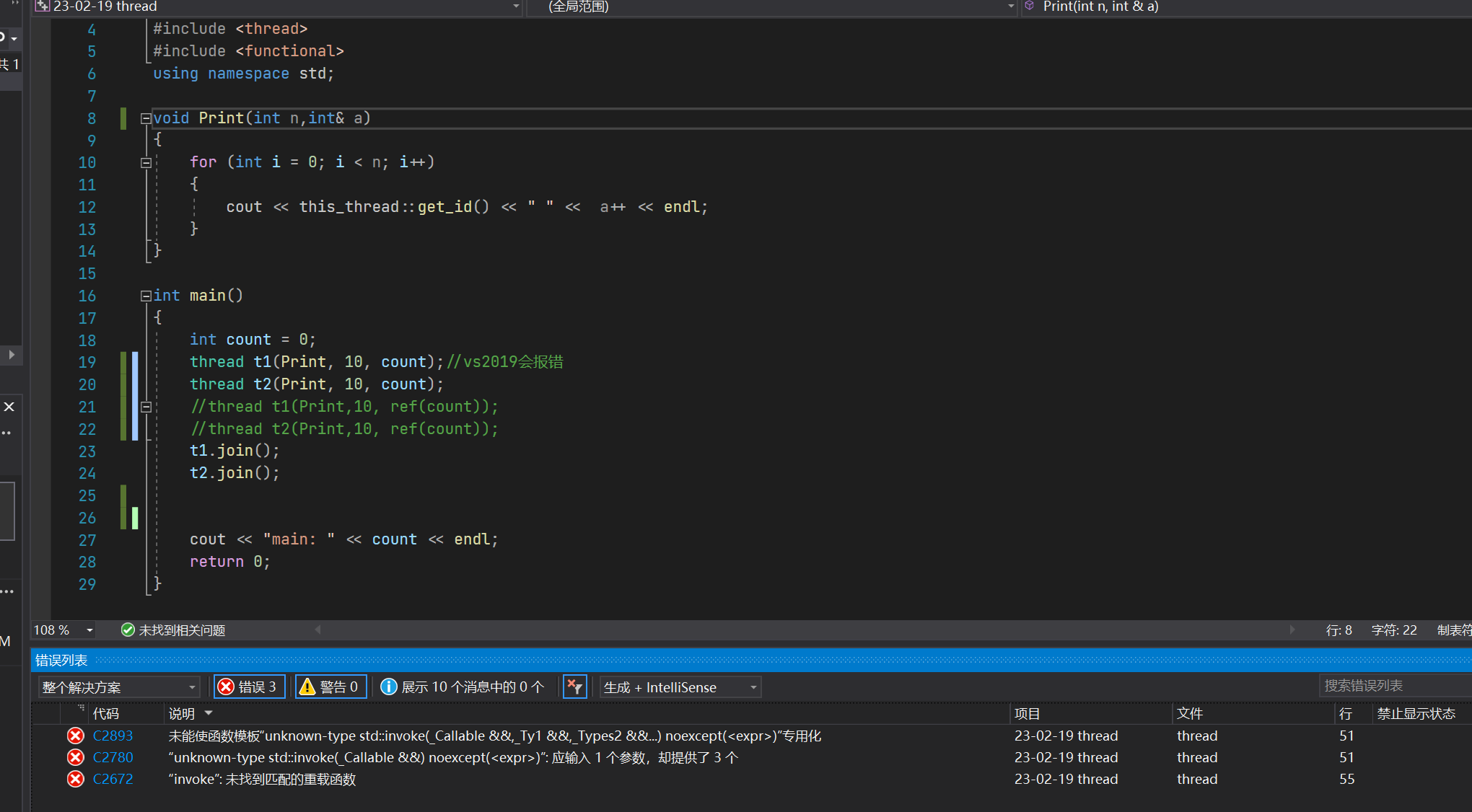
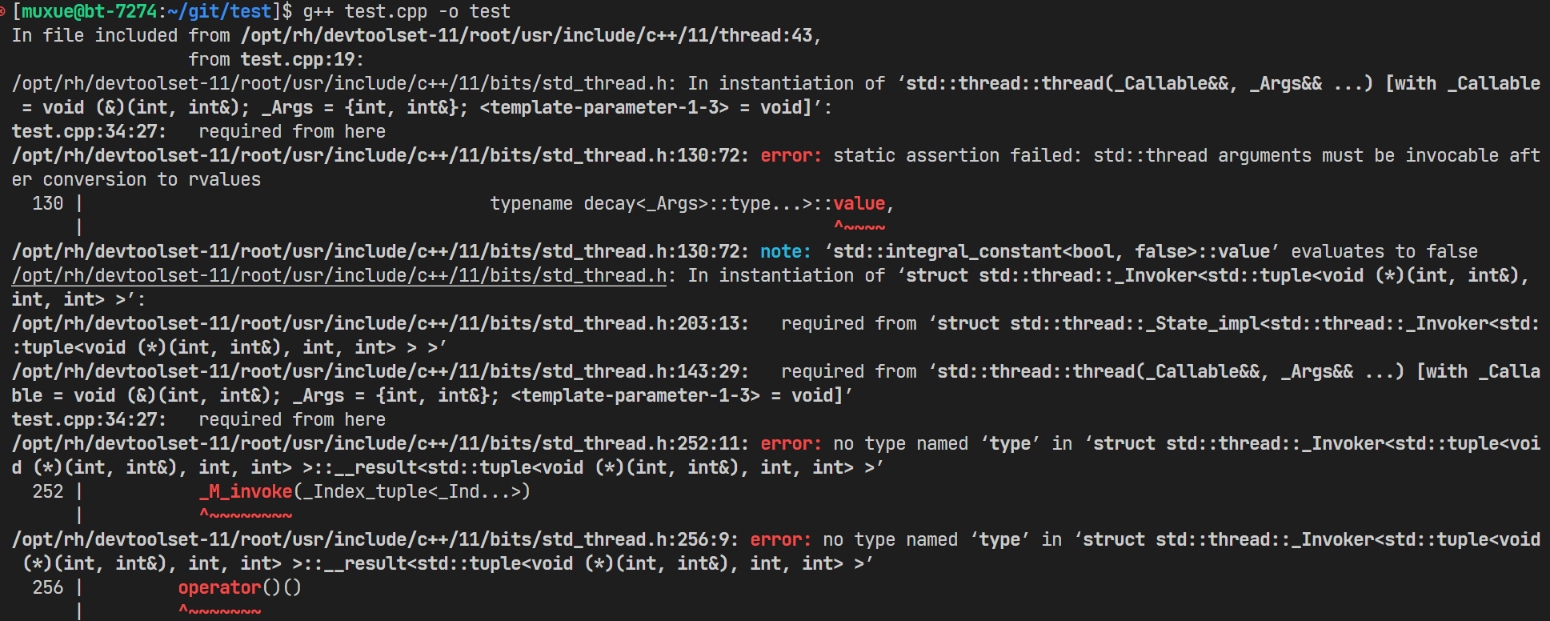
相同的代码在linux下也出现了编译错误,所用g++版本如下
g++ (GCC) 11.2.1 20220127 (Red Hat 11.2.1-9)
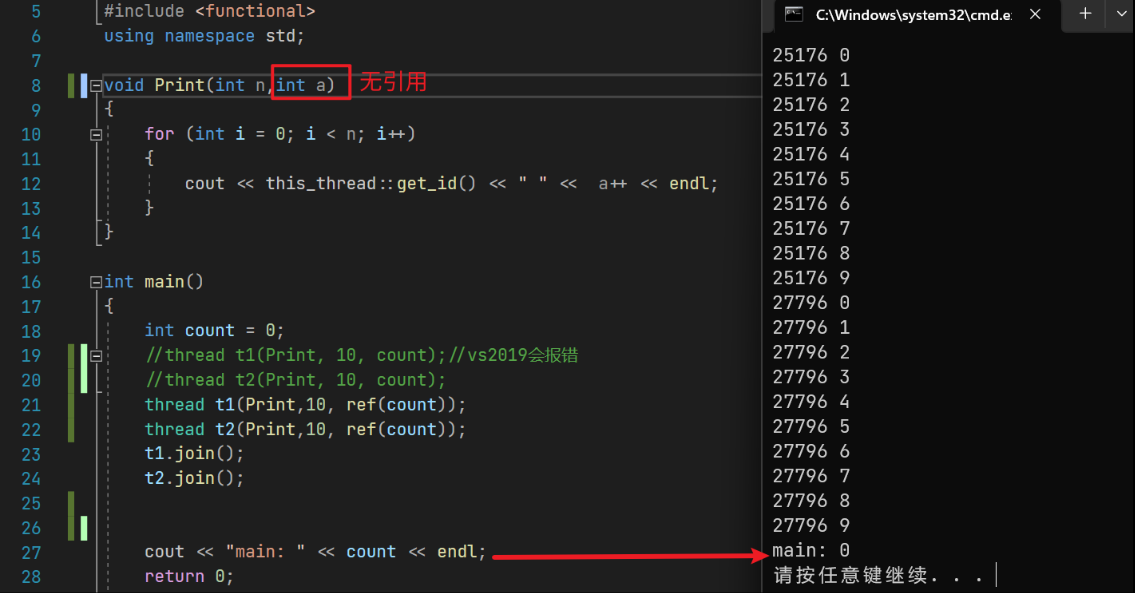
为了确认具体的报错位置,我们先把int& a的引用去掉,再看看情况
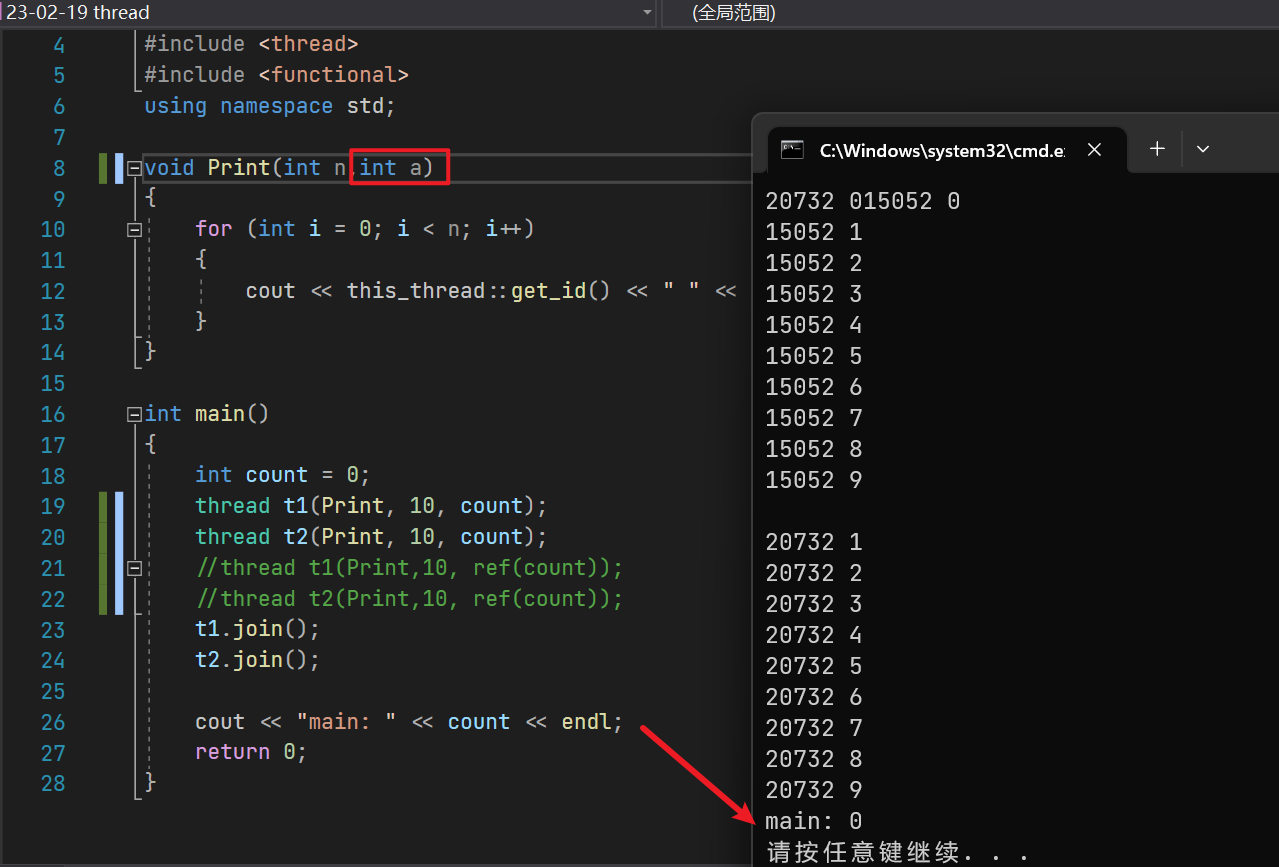
能看到,在没有采用引用传参的情况下,函数中对count进行的操作并不会反馈到main中,因为采用的是传值,会进行拷贝。
3.2 thread构造函数
那为什么加上引用之后,会报错呢?这就和thread的构造函数有关系了
template <class Fn, class... Args>
explicit thread (Fn&& fn, Args&&... args);
如上,当我们构造一个线程对象的时候,采用的是可变模板参数;在我的博客中写到过,可变模板参数需要采用递归来进行参数类型的推测。
由于底层实现的问题(也只能是这个原因了)在进行构造的完美转发时,所有的参数都采用了拷贝而不是引用传参。
这也就导致我们没有办法将一个参数通过引用传入线程需要执行的函数!
用指针肯定是可以的,可C++搞出引用这个东西,就是为了避免使用指针
3.3 ref出场
https://legacy.cplusplus.com/reference/functional/ref/?kw=ref
于是乎,std库中就新增了一个库函数ref,来解决这个问题
// ref的用法
template <class T> reference_wrapper<T> ref (T& elem) noexcept;
template <class T> reference_wrapper<T> ref (reference_wrapper<T>& x) noexcept;
template <class T> void ref (const T&&) = delete;
Constructs an object of the appropriate reference_wrapper type to hold a reference to elem.
If the argument is itself a reference_wrapper (2), it creates a copy of x instead.
The function calls the proper reference_wrapper constructor.
这个函数会构造一个合适的reference_wrapper对象,来管理一个变量的引用。如果参数本身就是reference_wrapper类型,则会调用reference_wrapper的拷贝构造。
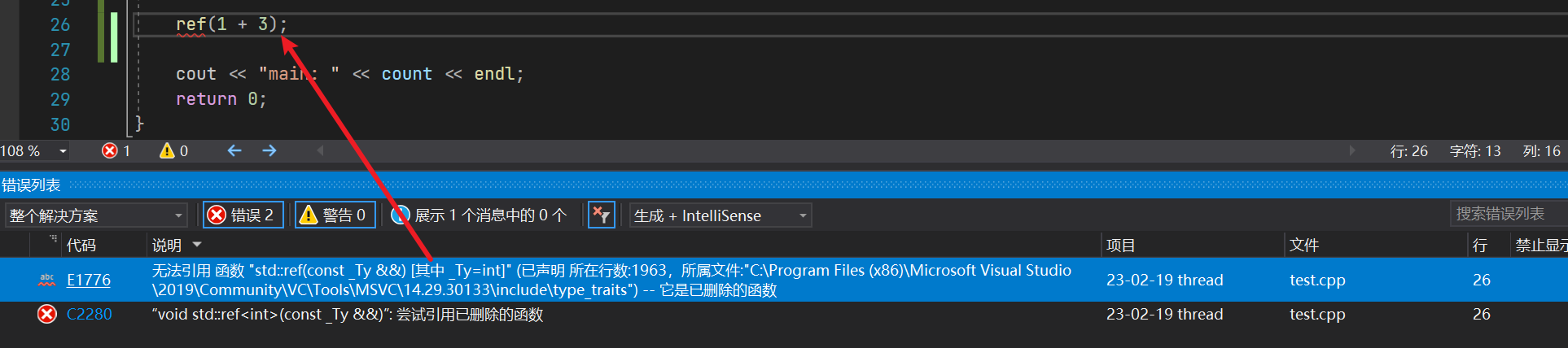
而ref函数不能传递右值,其右值引用的重载是被delete的
3.4 ref使用
thread t1(Print,10, ref(count));thread t2(Print,10, ref(count));t1.join();t2.join();
使用了该库函数之后,编译不再报错,main中的值也成功被修改
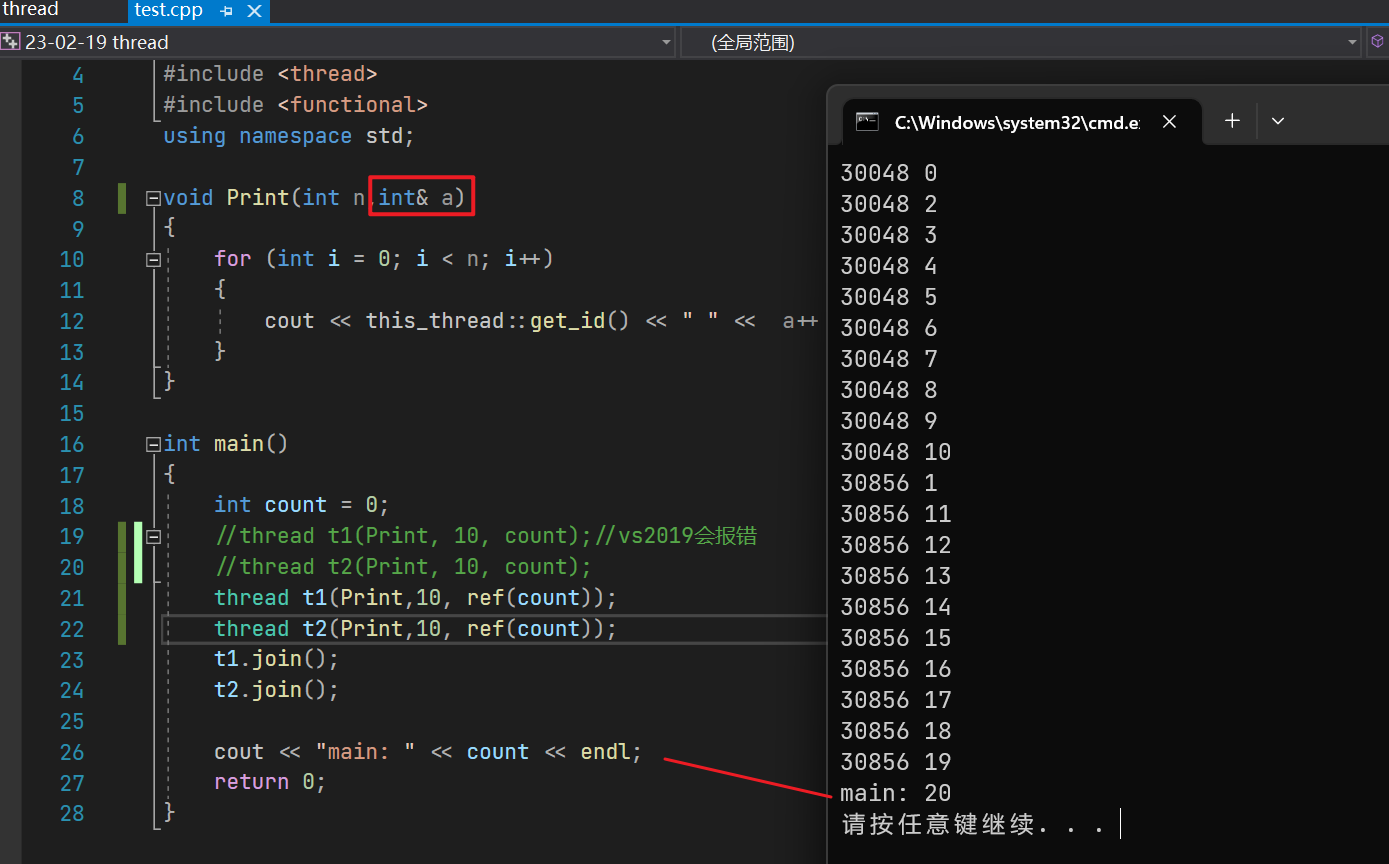
通过ref传递的参数,也会遵守函数本身的变量规则。如果函数本身没有采用引用传参,则还是调用传值参数,会进行拷贝;
为了避免后续出现这种问题,可以给所有对线程的左值传参都带上ref😏比如给两个线程函数传入同一把锁的时候,就需要采用ref进行引用传参
4.指令重排
谈谈指令重排 - 知乎
面试官: 有了解过指令重排吗,什么是happens-before
4.1 什么是重排序
首先,什么是重排序❓计算机在执行过程中,为了提高性能,会对编译器和编译器做指令重排。
这么做为啥可以提高性能呢❓
我们知道计算机在执行的时候都是一个个指令去执行,不同的指令可能操作的硬件不一样,在执行的过程中可能会产生中断。
打个比方,两个指令a和b他们操作的东西各不相同,如果加载a的时候停顿了,b就加载不到,但是实际上它们互补影响,我也可以先加载b在加载a,所以指令重排是减少停顿的一种方法,这样大大提高了效率。
4.1.1 指令重排的方式
指令重排一般分为以下三种
编译器优化重新安排语句的执行顺序指令并行重排利用指令级并行技术将多个指令并行执行,如果指令之前没有数据依赖,处理器可以改变对应机器指令的执行顺序内存系统重排由于处理使用缓存和读写缓冲区,所以它们是乱序的
指令重排可以保证串行语义一致,但是没有义务保证多线程间的语义也一致**。所以在多线程下,指令重排序可能会导致一些问题
4.2 实际场景
以懒汉的单例模式为例
// 获取单例对象
static InfoMgr* GetInstance()
{if (_sp == nullptr)//第一次检测保证单例{unique_lock<mutex> lock(_mtx);if (_sp == nullptr)//第二次检测保证线程安全{_sp = new InfoMgr;}}return _sp;
}
一般情况下,new一个新对象,执行的顺序应该是这样的
operator new
构造对象
赋值给_sp
但编译器如果进行了指令重排,可能就会变成这样
operator new
赋值给_sp
构造对象
如果一个线程执行到第二步赋值给_sp的时候,因为时间片到了被切换走了;其他线程来获取单例,就会导致_sp变量是一个已经被赋值了,但是其指向的是没有初始化的空对象,这是错误的!
4.3 可行的解决办法:内存栅栏
所谓内存栅栏,是系统提供的的接口,用于禁止cpu对指令的优化;
https://blog.csdn.net/qq_16498553/article/details/128030833
但内存栈栏是系统接口,没有跨平台性;这里只做了解,知道有这个问题即可!
在一般情况下,我们不需要担心4.2中提到的问题,因为指令优化是有严格规则的,不会对赋值和构造这类指令进行胡乱优化(因为这样优化并不会有效率提升啊)
但这也需要看具体平台的底层实现了!
5.获取线程返回值
5.1 输出型参数
在C语言中,想获取线程返回值,需要使用输出型参数(C++可以用引用传值)
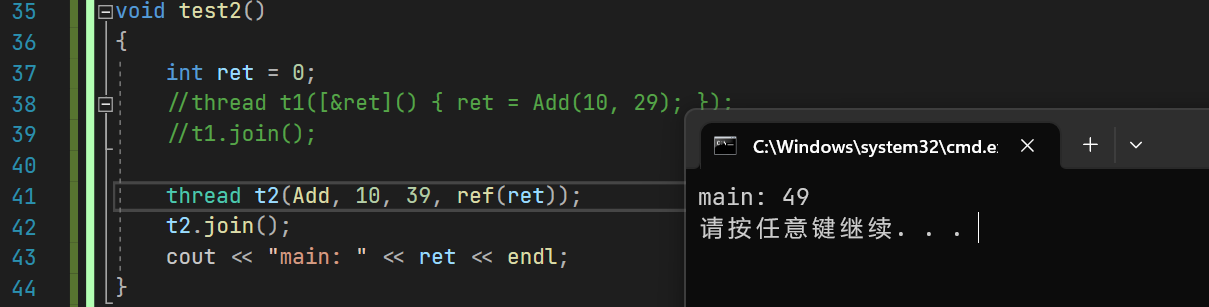
int Add(int a, int b,int& out)
{out = a + b;return out;
}
void test2()
{int ret = 0;thread t2(Add, 10, 39, ref(ret));t2.join();cout << "main: " << ret << endl;
}
5.2 lambda
在C++中,还可以使用lambda表达式,来在main中获取线程的返回值
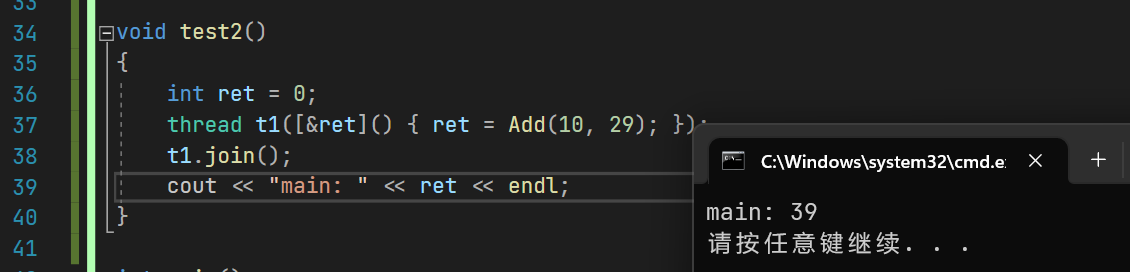
int Add(int a, int b)
{return a + b;
}void test2()
{int ret = 0;thread t1([&ret]() { ret = Add(10, 29); });t1.join();cout << "main: " << ret << endl;
}
6.函数重载问题
在我测试的时候发现,如果一个函数具有重载,线程是不支持的;
具体的原因嘛,我猜和线程构造的可变模板参数有关系。
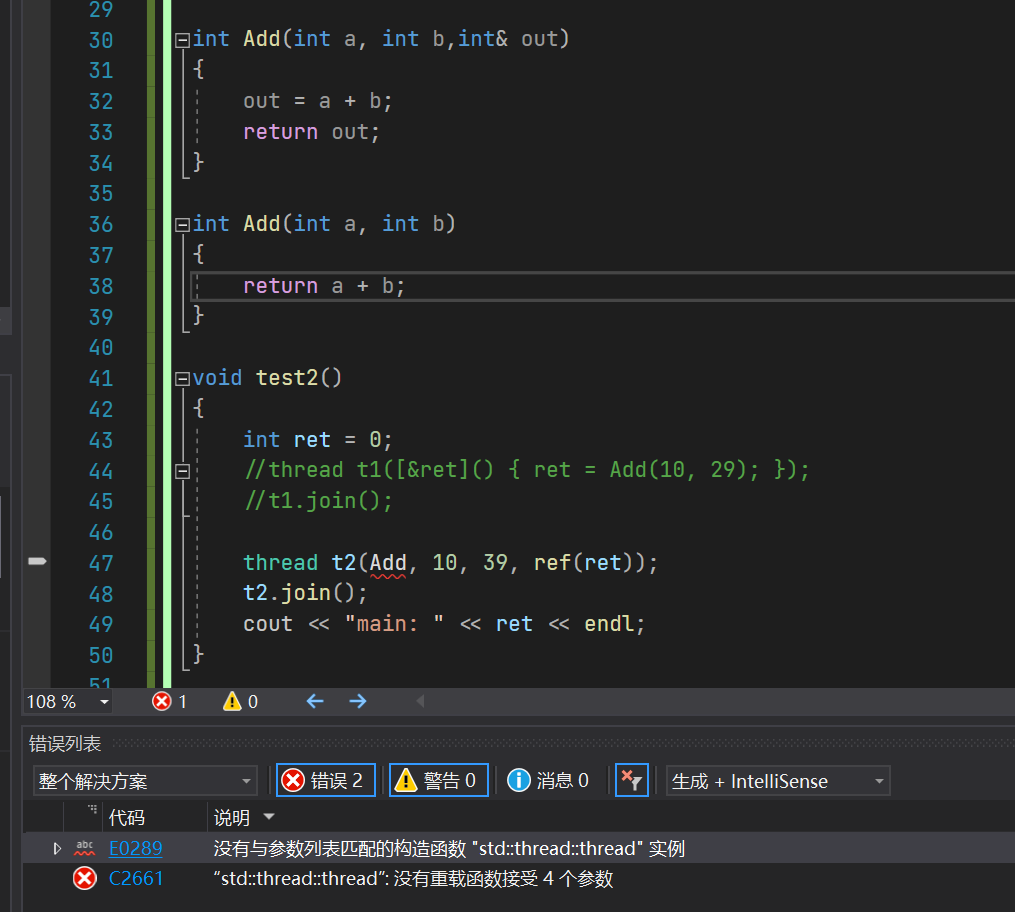
百度了一下,解决办法,是给第一个参数传入一个函数指针或者fuctional对象,手动指定使用的是哪一个函数。
当然,还有一个解决办法:线程调用的函数不要有重载😂
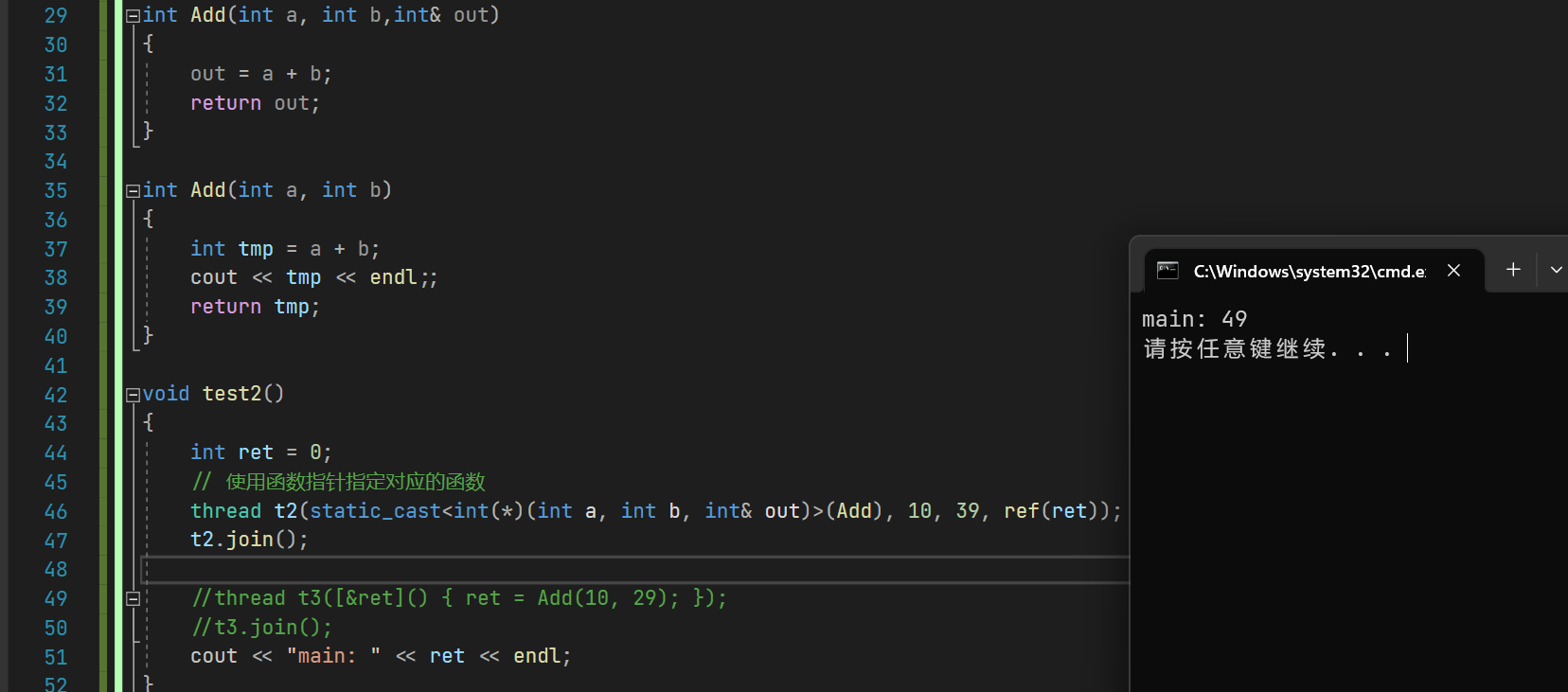
int Add(int a, int b,int& out)
{out = a + b;return out;
}int Add(int a, int b)
{int tmp = a + b;cout << tmp << endl;;return tmp;
}void test2()
{int ret = 0;// 使用函数指针指定对应的函数thread t2(static_cast<int(*)(int a, int b, int& out)>(Add), 10, 39, ref(ret));t2.join();cout << "main: " << ret << endl;
}
7.this_thread
std库中还用命名空间对线程的一些操作进行了封装
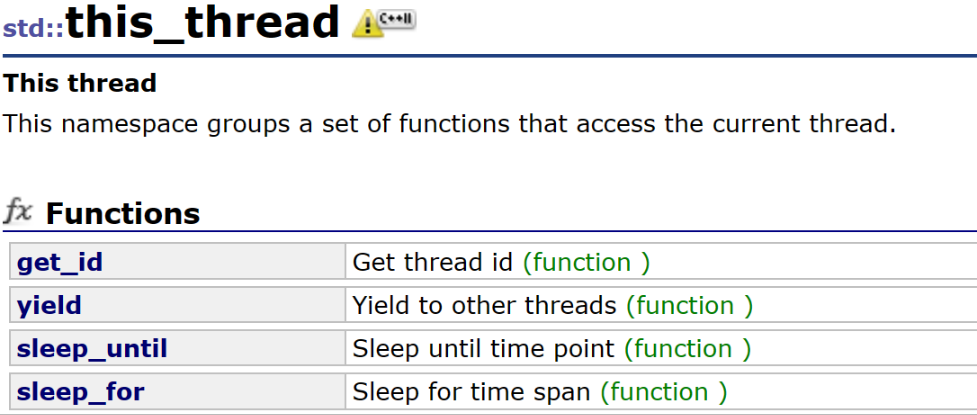
- get_id 获取线程id号(其实线程类里面已经有这个东东了,但是为了方便函数中直接调用,又多开了一个函数)
- yield 放弃自己的时间片
- sleep_until 休眠到一个时间点(比如睡到明天早八)
- sleep_for 休眠一定时间(睡2分钟)
下面来对后面三个函数做一点解释(第一个就不解释了哈)
7.1 yield
yield的作用是让出当前线程的时间片;
我们知道每一个线程运行时都会有一个自己的时间片,时间片到了,就会进行线程的切换;
以下面的场景为例
volatile bool ready = false;void count1m(int id)
{// 如果main没有设置ready信号,线程会一直让出自己的时间片,不会运行while (!ready) { this_thread::yield();}// 开始运行,++数据volatile int i = 0;for (i=0; i < 10000000; i++) { ; // 循环体啥都不干}cout << id;
}void test4()
{thread threads[10];cout << "创建10个线程 计数\\n";for (int i = 0; i < 10; ++i) {threads[i] = thread(count1m, i);}cout << "创建10个线程 完毕\\n";ready = true;//设置状态,让线程开始运行cout << "main set ture: " << ready << "\\n";for (auto& th : threads) {th.join();}cout << "\\nmain join 成功" << "\\n";
}
执行结果
创建10个线程 计数
创建10个线程 完毕
main set ture: 1
3746089215
main join 成功
在这个场景中,每一个线程被设置了task后,都会先进入一个while循环,等待主线程进行ready的设置
while (!ready) { ;}
此时我们就可以在while循环中进行yield让线程让出自己的时间片。否则这个线程会一直疯狂访问ready,导致cpu占用提高。
// 如果main没有设置ready信号,线程会一直让出自己的时间片,不会运行while (!ready) { this_thread::yield();}
在这种轮询检测的场景下,使用yield能避免某一个线程长时间占用执行流,解决了其他线程的饥饿问题。
7.2 sleep_until
用cplusplus的示例代码来学习使用方法,这里涉及到了多个库函数,详见注释
#include <iostream>
#include <thread>
#include <chrono> //std::chrono
#include <iomanip> //std::put_time
#include <ctime> //std::time_t, std::tm, std::localtime, std::mktime
using namespace std;// 直接把main当作一个线程
void test5()
{time_t tt = chrono::system_clock::to_time_t(chrono::system_clock::now()); // 获取当前时间的时间戳struct tm* ptm = localtime(&tt); // 设置一个tm结构体,从当前时间戳创建cout << "Current time: " << put_time(ptm, "%X") << '\\n'; // 打印当前时间cout << "Waiting for the next minute to begin...\\n";(ptm->tm_min)++; // 设置ptm的min为下一分钟ptm->tm_sec = 0; // 下一分钟的第0sthis_thread::sleep_until(chrono::system_clock::from_time_t(mktime(ptm))); // 等待下一分钟开始运行cout << put_time(ptm, "%X") << " reached!\\n"; // 再次打印当前时间
}
运行结果如下,会等到下一分钟的第0s继续执行
Current time: 15:13:40
Waiting for the next minute to begin...
15:14:00 reached!
7.3 sleep_for
这个函数的作用和windows、linux下都有的sleep函数一样,是睡指定的时间
需要用std中的chrono模块来指定运行的时间,支持从小时一直到纳秒
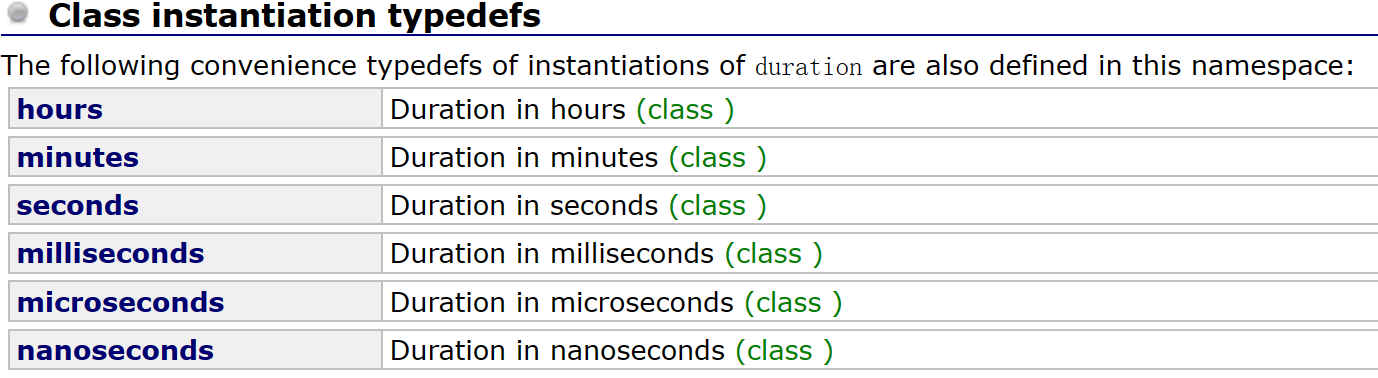
示例如下
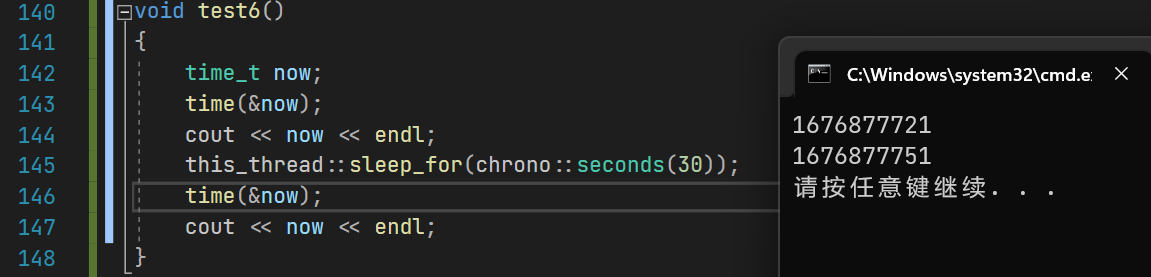
void test6()
{time_t now;time(&now);//获取当前时间戳cout << now << endl;this_thread::sleep_for(chrono::seconds(30));//睡30stime(&now);//获取当前时间戳cout << now << endl;
}
可以看到,进程确实休眠了30s
8.mutex
有了线程,那肯定离不开锁;关于线程加锁的问题,详见我的linux博客
这里只对C++中锁的只用方法做一定演示
8.1 构造

锁的构造相对较简单,只有一个无参的构造,其不支持拷贝构造(比如函数传参中,一个锁被拷贝了,就失去了意义)
8.2 成员函数
其余成员就是一个锁的基本接口,对应的也是pthread_mutex中的几个接口
- lock 加锁,不能申请锁则阻塞等待
- try_lock 测试是否能申请锁,不能申请则return
- unlock 解锁

8.3 场景
所谓加锁,保护的就是临界资源;比如在下面的代码示例中,全局变量count1就是一个临界资源,其能够被多个执行流访问。
注意:如果你展开了std命名空间,其中有一个count函数,会和你自己定义的全局count变量冲突。刚开始我就定义了count,发现报错变量不明确。
#define TOP 100
volatile int count1 = 0;void func()
{while(1){if (count1 == TOP){break;}cout << this_thread::get_id() << " : " << count1++ << endl;this_thread::sleep_for(chrono::milliseconds(10));}cout << this_thread::get_id() << " : " << count1 << endl;
}void test7()
{thread threading[10];for (int i = 0; i < 10; i++){threading[i] = thread(func);}for (int i = 0; i < 10; i++){threading[i].join();}cout << "main: " << count1 << endl;this_thread::sleep_for(chrono::seconds(2));
}
测试的时候,就能看到一个很明显的冲突结果。31752线程已经++到100了,结果它努力的结果被其他两个线程直接复写;
当然,这里也有可能是显示器乱序打印的结果。要知道,显示器也是一个临界资源

mutex mtx;void func()
{while(1){ if (count1 == TOP){break;}// 加锁的粒度要低mtx.lock();cout << this_thread::get_id() << " : " << count1++ << endl;mtx.unlock();this_thread::sleep_for(chrono::milliseconds(10));}cout << this_thread::get_id() << " : " << count1 << endl;
}
给访问count的函数添加上锁,就能避免掉上面出现的问题
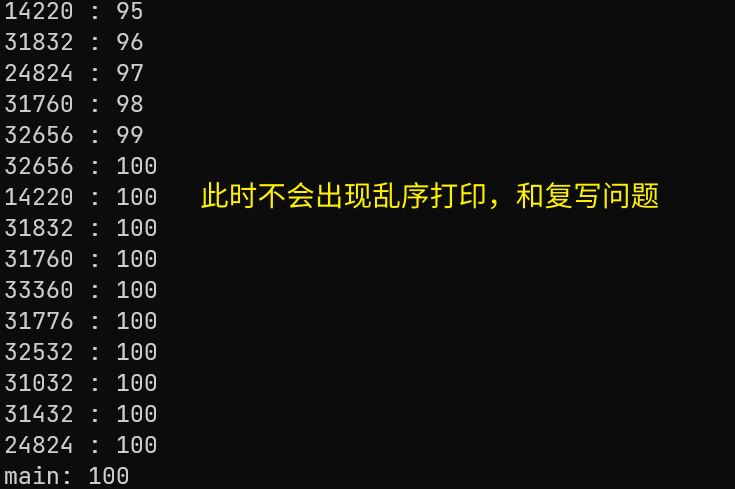
9.CAS原子操作
在系统中,提供了一些指令,来实现原子操作!
9.1 原理
Compare And Set(或Compare And Swap),简称CAS。其是解决多线程并行情况下使用锁造成性能损耗的一种机制,采用这种无锁的原子操作可以实现线程安全,避免加锁的笨重性。
CAS操作包含三个操作数:内存位置(V)、预期原值(A)、新值(B)
具体操作流程请看下图:
如果上面的图看不懂,还可以看下面这个图
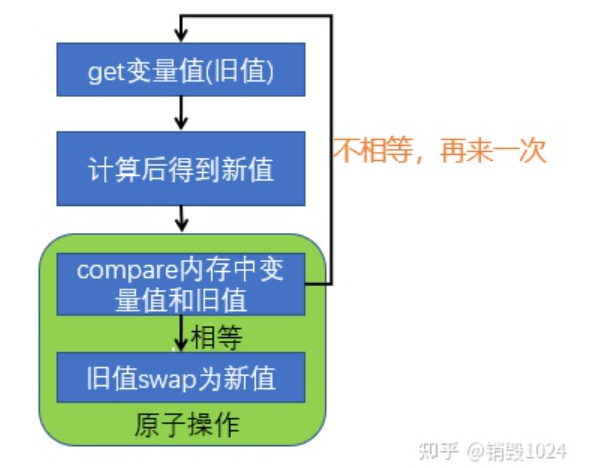
文字描述如下:
- 如果内存位置的值(V)与预期原值(A)相同,处理器会将该位置的值更新为新值(B) CAS 操作成功!
- 否则,处理器不做任何更改,只需要将当前位置的值进行返回即可
CAS是实现自旋锁的基础,CAS 利用CPU指令保证了操作的原子性,以达到锁的效果,循环这个指令,直到成功为止。
9.2 问题
CAS也不是万能的,其在如下场景下可能会出现问题
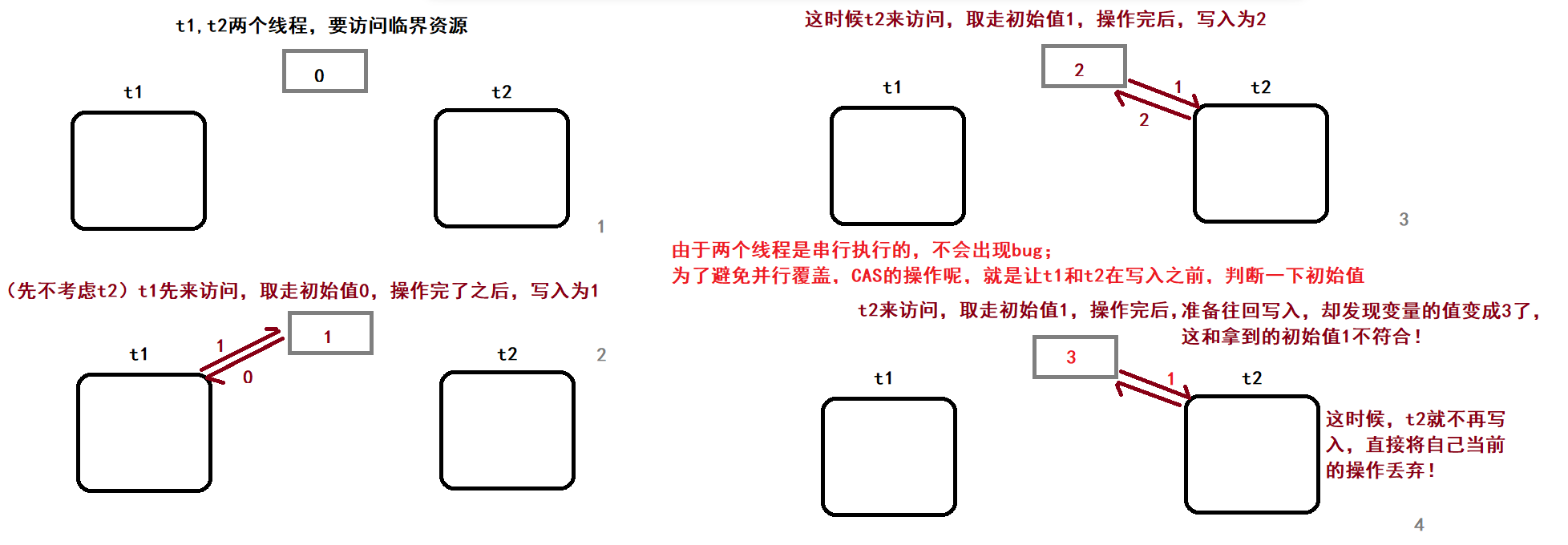
1.有线程a和b
2.有全局变量,初始值为1
3.线程a先来访问,拿走了初始值1
4.发生线程切换,线程b来访问,拿走初始值1,更新为2,又修改回1
5.发生线程切换,线程a继续访问,此时值依旧是1,线程a会认为没有问题,写入
你可以看到,在上面的场景中,有一个线程把全局变量修改了之后又改了回去,这时候就没有办法从取值判断变量是否还是“原来的那个”了
针对这种情况,java并发包中提供了一个带有标记的原子引用类"AtomicStampedReference",它可以通过控制变量值的版本来保证CAS的正确性。
C/C++中有没有办法解决这个问题呢?我没百度到😂
10.lock_guard
人如其名,这个类是一个守护锁。
template <class Mutex> class lock_guard;
其运用了RAII的思路,能在构造的时候加锁,析构的时候解锁。我们就不需要自己操作了。
毕竟,代码一长起来,一个锁有没有被解开,是真的搞不清楚😥
mutex mtx;
void test7()
{int x = 0;int n = 0;int m = 1000000;cin >> n;vector<thread> threading(n);for (int i = 0; i < n; i++){threading[i] = thread([&]() {for (int i = 0; i < m; i++){lock_guard<mutex> t(mtx);//自动加锁解锁x++;}});}for (int i = 0; i < n; i++){threading[i].join();}cout << "main: " << x << endl;
}
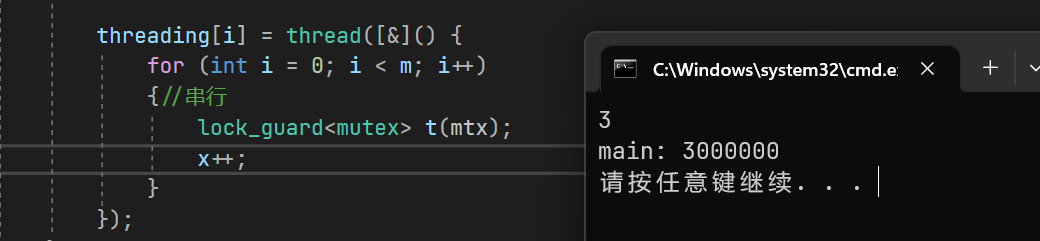
如果for循环中需要执行的代码很多,而只有x是临界资源的话,那就需要我们手动控制一下作用域{}
for (int i = 0; i < m; i++){//其他代码{lock_guard<mutex> t(mtx);//自动加锁解锁x++;}//其他代码}
11.unique_lock
template <class Mutex> class unique_lock;
如果你学习过智能指针,那肯定就知道这个命名的含义;
unique_lock是lock_graud的增强版本,其在支持自动加锁解锁的前提下,还支持手动加锁解锁;
11.1 使用示例
下面就是一个标准的使用场景
threading[i] = thread([&]() {for (int i = 0; i < m; i++){unique_lock<mutex> t(mtx);//自动加锁x++;t.unlock(); //手动解锁// 模拟其他工作this_thread::sleep_for(chrono::milliseconds(100));// 又需要访问临界资源t.lock();// 手动解锁x++;}// 出作用域,自动解锁});
11.2 try_lock
除了最基础的try_lock之外,这个类还支持for和until,和this_thread中的sleep是一样的含义
try_lock
Lock mutex if not locked (public member function )try_lock_for
Try to lock mutex during time span (public member function )
加锁一直到指定时间解锁(加锁到明天早八)try_lock_until
Try to lock mutex until time point (public member function )
加锁xx时间(加锁100秒,时间到了自动解锁)
时间到了之后,这个函数会进行解锁。如果用户在这之前已经手动解锁了,则什么都不会做
11.3 release
这个函数的作用就很独特了,其将自己管理的锁释放掉,不再管理这个锁
mutex_type* release() noexcept;
调用这个函数会返回托管互斥对象的指针,释放其所有权。调用后,unique_lock对象不再管理任何互斥对象(即,它处于与if默认构造相同的状态)。
注意,此函数不会锁定或解锁返回的互斥对象。
说人话就是,不需要你RALL来管理这个锁了,交给用户自己管理!
12.share_ptr
share_ptr的完整代码请看我的 Gitee
在智能指针中,share_ptr采用引用计数来判断有多少次拷贝(拷贝构造、赋值重载),只有拷贝计数器为1的时候,析构才需要释放资源。
在share_ptr内部有一个变量进行计数。既然有一个计数变量,那就需要保证多线程执行时的原子性!
12.1 引用计数加锁
void AddRef()//新增引用{_pMutex->lock();++(*_pRefCount);_pMutex->unlock();}
12.2 释放
void Release(){bool flag = false;//判断锁是否需要被释放_pMutex->lock();if (--(*_pRefCount) == 0 && _ptr){//进入了这个函数,代表引用计数为0delete _ptr;delete _pRefCount;//标识需要释放锁flag = true;}_pMutex->unlock();//解锁//释放锁if (flag){delete _pMutex;}}
12.3 注意事项
share_ptr的加锁只限于这个类对象本身的安全性,这个锁并不是用来保护share_ptr所指向的资源的!
13.atomic
在全局变量中,计数器是很常用的类型。所以C++中还提供了一个可以进行原子操作的类,对这个变量进行的操作是具有原子性的,不需要我们进行加锁解锁
template <class T> struct atomic;
13.1 基本使用
atomic<int> val=0;void test8()
{cout << val << endl;val++;cout << val << endl;val = 20;cout << val << endl;val--;cout << val << endl;
}
如果是int类型,原子变量和普通的int变量的使用没有什么区别!
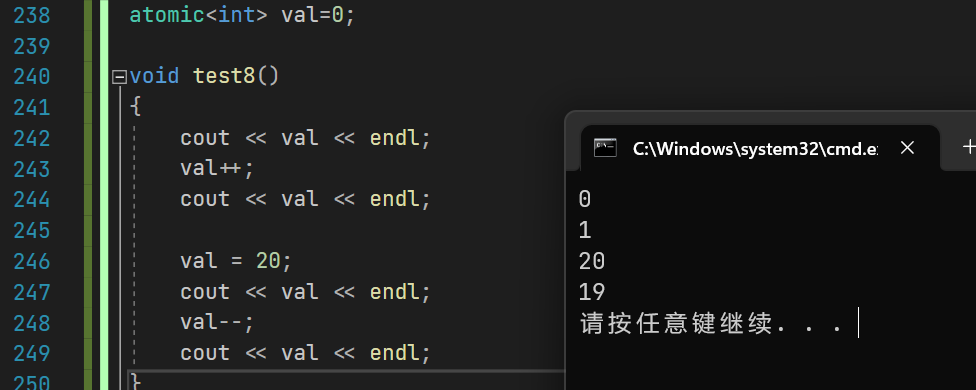
可以看到,重载了以后,原子变量支持++ --,也支持直接赋值

不过,这些方法标明了,只有整形家族和指针类型可以使用!

13.2 operator =
原子变量可以直接赋值,是因为其重载了 operator =
//set value (1)
T operator= (T val) noexcept;
T operator= (T val) volatile noexcept;
//copy [deleted] (2)
atomic& operator= (const atomic&) = delete;
atomic& operator= (const atomic&) volatile = delete;
13.3 operator T/load
operator T 的作用,是支持隐式类型转换,这样原子变量在进行if比较的时候,会转换成重载后的类型
operator T() const volatile noexcept;
operator T() const noexcept;
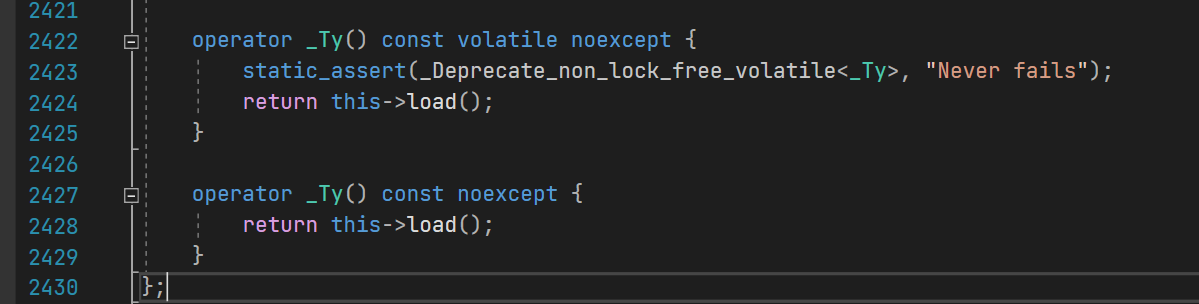
在vs2019里面跳转源码,能看到重载后的这两个函数,其实是调用了load方法
template <class _Ty>
struct atomic : _Choose_atomic_base_t<_Ty>{//...operator _Ty() const volatile noexcept {static_assert(_Deprecate_non_lock_free_volatile<_Ty>, "Never fails");return this->load();}operator _Ty() const noexcept {return this->load();}
}
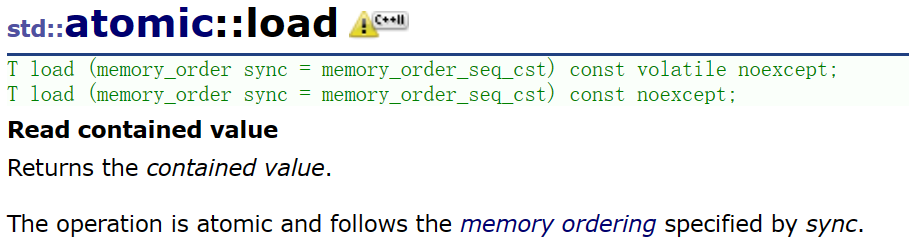
查看cplusplus的解释,load方法就是返回了其内部所包含的值
T load (memory_order sync = memory_order_seq_cst) const volatile noexcept;
T load (memory_order sync = memory_order_seq_cst) const noexcept;
这里还特意标注了,load方法的使用是原子性的
13.4 exchange
T exchange (T val, memory_order sync = memory_order_seq_cst) volatile noexcept;
T exchange (T val, memory_order sync = memory_order_seq_cst) noexcept;
exchange函数的作用是修改原子变量管理的值,其返回值是修改之前的变量
Return value
The contained value before the call.
T is atomic's template parameter (the type of the contained value).
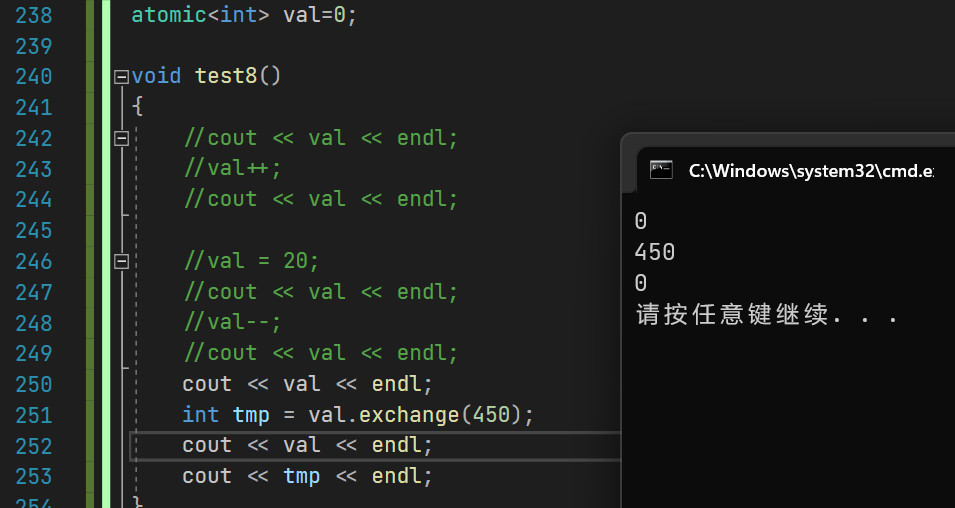
以下面的代码为例
atomic<int> val=0;void test8()
{cout << val << endl;int tmp = val.exchange(450);cout << val << endl;cout << tmp << endl;
}
可以看到tmp接收到的结果是val的初始值0,val本身被修改为450
13.5 store
void store (T val, memory_order sync = memory_order_seq_cst) volatile noexcept;
void store (T val, memory_order sync = memory_order_seq_cst) noexcept;
这个函数的作用比exchange简单,其只修改存储的变量,没有返回值
关于原子变量的介绍就这么多,下面来康康C++中的条件变量
14.condition_variable
条件变量的概念,参考 linux 线程同步
14.1 构造和wait
条件变量,是用于线程同步操作的一个接口。在C++中,条件变量只有一个空构造
//default (1)
condition_variable();
//copy [deleted] (2)
condition_variable (const condition_variable&) = delete;
当我们进行wait等待的时候,需要往条件变量内传入一个锁;进入wait函数,开始等待前会先解锁,退出函数前会加锁。
//unconditional (1)
void wait (unique_lock<mutex>& lck);
//predicate (2)
template <class Predicate>void wait (unique_lock<mutex>& lck, Predicate pred);
wait函数除了传入锁,还可以传入一个Predicate pred可执行函数体,来判断条件变量是否满足;
如果指定了pred,则只有当pred返回false时,该函数才会阻塞;并且只有当它变为true时,通知才能解除阻塞线程(这对于检查虚假唤醒特别有用)
- 虚假唤醒,指的是一些代码错误的情况下,另外一个线程在条件尚未真正就绪的时候就唤醒了该线程
- 添加上判断条件,能在wait中判断条件是否已经真正满足,从而避免虚假唤醒
wait内部对pred的检测是下面这样
while (!pred()) wait(lck);
只有pred返回真的时候,才会跳出while循环,唤醒线程。
除了检测虚假唤醒,我们还可以用该执行体,对不同的线程指定不同的唤醒条件!
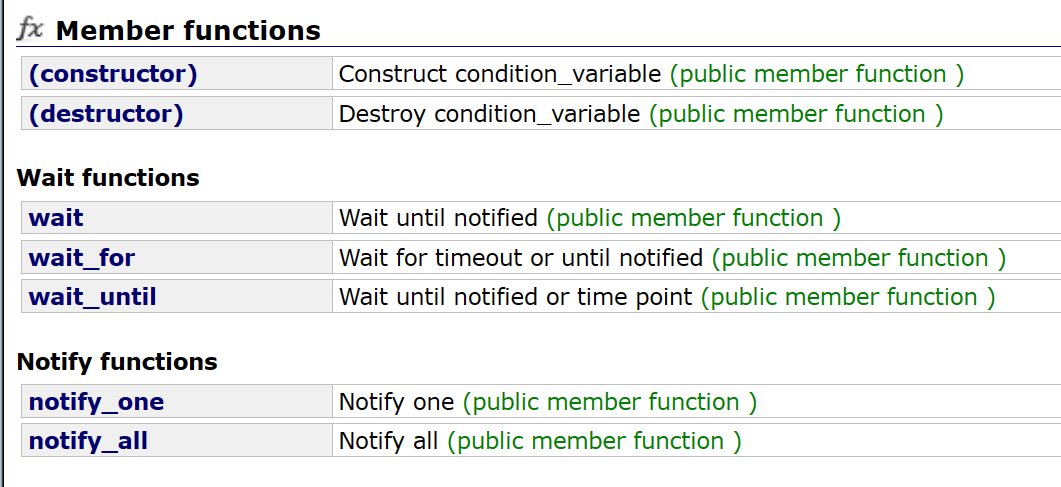
14.2 其他接口
其他接口的使用也很直接,其中wait_for和until前面已经介绍过了
- wait:在条件变量中阻塞等待,等待被唤醒
- notify_one:唤醒在该条件变量等待下的一个线程
- notify_all:唤醒在该条件变量下等待的所有线程
14.3 实际用例
当下我们有两个线程,我们的目标是让t1和t2线程共同管理一个变量i,对其进行++,并实现t1打印奇数,t2打印偶数的功能(二者交错打印)
void test9()
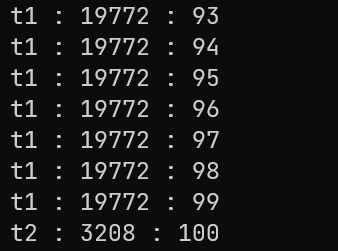
{// 目标:t1打印奇数,t2打印偶数,二者交错打印bool ready = true;int i = 0;int n = 100;mutex mtx;condition_variable cv;// t1打印奇数thread t1([&](){while (i < n){unique_lock<mutex> lock(mtx);cout << "t1 : " << this_thread::get_id() << " : " << i << endl;i++;}});// t2打印偶数thread t2([&]() {while (i < n){unique_lock<mutex> lock(mtx);cout <<"t2 : "<<this_thread::get_id() << " : " << i << endl;i++;}});this_thread::sleep_for(chrono::seconds(3));cout << "t1:" << t1.get_id() << endl;cout << "t2:" << t2.get_id() << endl;t1.join();t2.join();}
当下已经实现出了二者的基本操作,但直接运行我们会发现,t1都已经打印到99了,t2才开始执行,完全不符合交错打印的需求
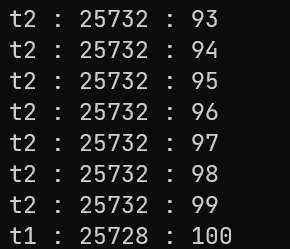
thread t1([&](){while (i < n){{unique_lock<mutex> lock(mtx);cout << "t1 : " << this_thread::get_id() << " : " << i << endl;i++;}this_thread::sleep_for(chrono::microseconds(100));}});
如果在t1的while循环中加上一个休眠,t2的函数体保持不变,则会发现是t2直接加到了99,才让可怜巴巴的t1访问了临界资源(饥饿问题)
这时候,我们就可以使用条件变量来实现线程相互唤醒和交错打印,代码如下
// 条件变量测试
void test9()
{// 目标:t1打印奇数,t2打印偶数,二者交错打印bool ready = true;int i = 0;int n = 100;mutex mtx;condition_variable cv;// t1打印奇数thread t1([&](){while (i < n){unique_lock<mutex> lock(mtx);//ready为假的时候,唤醒t1cv.wait(lock, [&ready](){return !ready; });cout << "t1 : " << this_thread::get_id() << " : " << i << endl;i++;ready = true;cv.notify_one();}});// t2打印偶数thread t2([&]() {while (i < n){unique_lock<mutex> lock(mtx);//ready为真的时候,唤醒t2cv.wait(lock, [&ready](){return ready; });cout <<"t2 : "<<this_thread::get_id() << " : " << i << endl;i++;ready = false;cv.notify_one();}});this_thread::sleep_for(chrono::seconds(3));cout << "t1:" << t1.get_id() << endl;cout << "t2:" << t2.get_id() << endl;t1.join();t2.join();}
运行一下,可以看到我们成功通过条件变量,使这两个线程交错打印奇偶数!
t2 : 23208 : 0
t1 : 24896 : 1
t2 : 23208 : 2
t1 : 24896 : 3
t2 : 23208 : 4
t1 : 24896 : 5
t2 : 23208 : 6
t1 : 24896 : 7
t2 : 23208 : 8
t1 : 24896 : 9
t2 : 23208 : 10
t1 : 24896 : 11
//....
t2 : 23208 : 90
t1 : 24896 : 91
t2 : 23208 : 92
t1 : 24896 : 93
t2 : 23208 : 94
t1 : 24896 : 95
t2 : 23208 : 96
t1 : 24896 : 97
t2 : 23208 : 98
t1 : 24896 : 99
t2 : 23208 : 100
即便在t1中额外加上休眠,也不会影响输出结果的准确性!
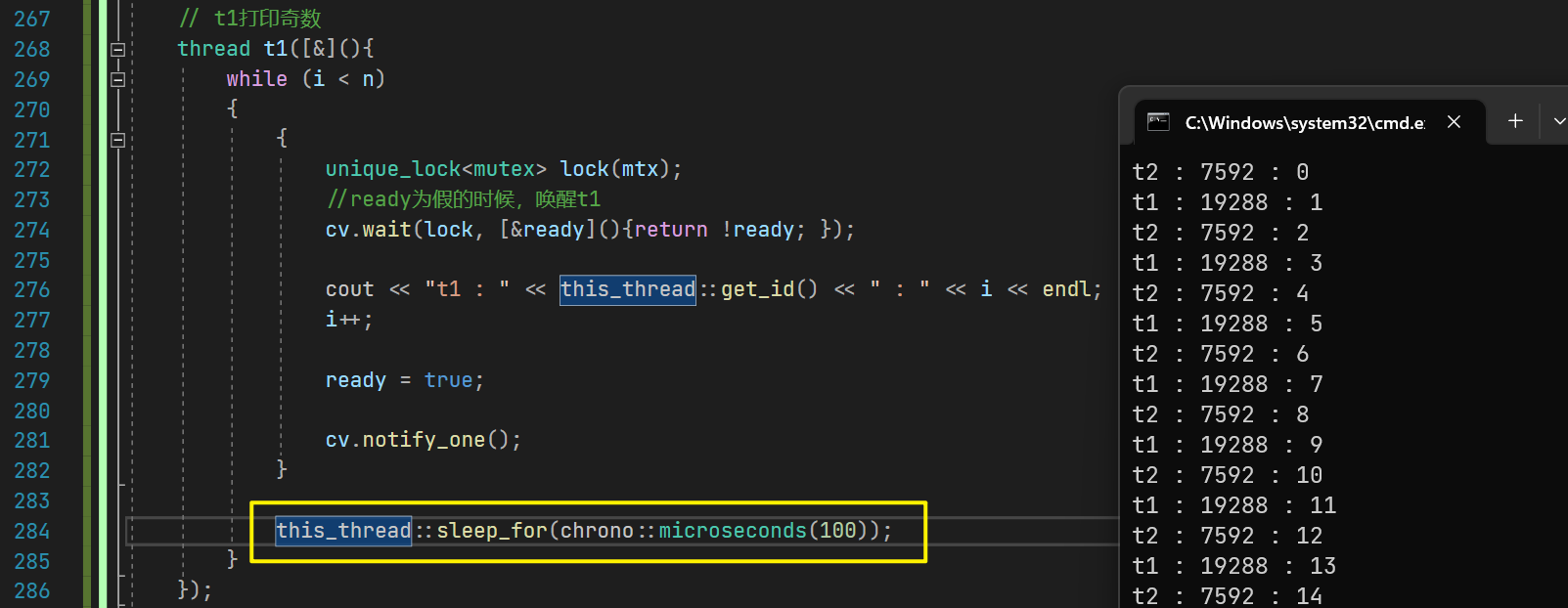
这便是条件变量对于线程同步控制的用法
结语
在学习过linux的线程基础和系统接口后,理解C++这里的多线程操作还算轻松!
C++语法学习的最后一块拼图也被补上了!