Java8的Optional类的使用 和 Stream流式操作

Java知识点总结:想看的可以从这里进入
目录
-
-
- 13.6、Optional类
- 13.7、Stream
-
- 13.7.1、Stream创建
- 13.7.2、中间操作
-
- 1、筛选
- 2、切片
- 3、映射
- 4、排序
- 13.7.3、终止操作
-
- 1、遍历
- 2、聚合
- 3、匹配查找
- 4、归约
- 5、收集
-
- 归集
- 统计
- 分组
- 字符串拼接
- 归约
-
13.6、Optional类
Optional类是一个可以为null的容器对象。如果值存在则isPresent()方法会返回true,调用get()方法会返回该对象。使用它提供很多有用的方法,我们就可以不用显式进行空值检测。Optional的引入极大的解决了关于空指针异常方面的问题。
| 序号 | 方法 & 描述 |
|---|---|
| 1 | static Optional of(T t): 创建一个 Optional 实例,t必须非空 |
| 2 | static Optional empty() :创建一个空的 Optional 实例 |
| 3 | static Optional ofNullable(T t):t可以为null,如果为null,返回空的 Optional,否则返回非空的 Optional实例 |
| 4 | void ifPresent(Consumer<? super T> consumer):如果有值,就执行Consumer接口的实现代码,并且该值会作为参数传给它。 |
| 5 | boolean isPresent():判断是否存在对象,存在则方法会返回true,否则返回 false。 |
| 6 | T get():如果在这个Optional中包含这个值,返回值,否则抛出异常:NoSuchElementException |
| 7 | T orElse(T other):如果有值则将其返回,否则返回指定的other对象。 |
| 8 | T orElseGet(Supplier<? extends T> other):如果有值则将其返回,否则返回由Supplier接口实现提供的对象 |
| 9 | T orElseThrow(Supplier<? extends X> exceptionSupplier):如果有值则将其返回,否则抛出由Supplier接口实现提供的异常。 |
| 10 | boolean equals(Object obj):判断其他对象是否等于 Optional。 |
| 11 | Optional filter(Predicate<? super predicate):如果值存在,并且这个值匹配给定的 predicate,返回一个Optional用以描述这个值,否则返回一个空的Optional。 |
| 12 | Optional flatMap(Function<? super T,Optional> mapper):如果值存在,返回基于Optional包含的映射方法的值,否则返回一个空的Optional |
| 13 | int hashCode():返回存在值的哈希码,如果值不存在 返回 0。 |
| 14 | Optional map(Function<? super T,? extends U> mapper):如果有值,则对其执行调用映射函数得到返回值。如果返回值不为 null,则创建包含映射返回值的Optional作为map方法返回值,否则返回空Optional。 |
| 15 | String toString():返回一个Optional的非空字符串,用来调试 |
Optional<String> s = Optional.of("张三");
System.out.println("s是否有值:"+s.isPresent());
System.out.println("如果存在返回否则返回不存在:"+s.orElse("不存在"));
System.out.println("获取值:"+s.get());

13.7、Stream
Stream是JDK8版本中除了Lambda 表达式外最重要的改变。Stream将要处理的元素集合看作一种流,在流的过程中,借助Stream API 对流中的元素进行筛选、排序、聚合等操作。使用Stream API 对集合数据进行操作,类似于使用 SQL 执行的数据库查询。它保存的数据的类型为Optional类型
Stream 自己不会存储元素,它只是对集合数据进行操作,它在操作时不改变原有的数据,而是返回一个新的Stream,同事它的操作是有延迟的,只会在需要结果的时候才执行。
它和以前的Collection操作不同, Stream操作还有两个基础的特征:
- Pipelining: 中间操作会返回流对象本身。 这样多个操作可以串联成一个管道, 这样做可以对操作进行优化, 比如延迟执行(laziness)和短路( short-circuiting)。
- 内部迭代: 以前对集合遍历都是通过Iterator或者For-Each的方式, 显式的在集合外部进行迭代, 这叫做外部迭代。 Stream提供了内部迭代的方式, 通过访问者模式(Visitor)实现。
我们可以把Stream的操作看成一个管道,分为三个步骤,首先创建Stream,然后对管道中的数据进行中间操作,最后获得处理的结果。
- Stream的创建
- Stream 的中间操作
- Stream 的终止操作
13.7.1、Stream创建
-
通过集合的方式:
JDK8中 Collection 接口被扩展提供了2个方法:
default Stream stream() :返回一个顺序流,由主线程按顺序对流执行操作
default Stream parallelStream() :返回一个并行流,内部以多线程并行执行的方式对流进行操作
List<String> list = new ArrayList<>(); //创建顺序流 Stream<String> listStream = list.stream(); //创建并行流 Stream<String> parallelStream = list.parallelStream(); -
根据数组创建:java.util.Arrays.stream(T[] array)
int[] nums = {1,2,3,4,5,6}; IntStream arraysStream = Arrays.stream(nums); -
使用Stream的静态方法:
-
of():返回其元素为指定值的顺序有序流。

-
Stream.of().parallel():创建一个并行流
-
iterate():返回通过将函数f迭代应用到初始元素seed产生的无限顺序有序Stream ,产生由seed 、 f(seed) 、 f(f(seed))等组成的Stream 。

-
generate():返回无限顺序无序流,其中每个元素都由提供的Supplier生成。

-
13.7.2、中间操作
1、筛选
-
筛选:按照一定的规则校验流中的元素,将符合条件的元素提取到新的流中的操作。
-
filter(Predicate p):通过Lambda表达式设置规则 , 从流中获取元素
@Test public void main(){List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);Stream<Integer> stream = list.stream();//筛选出集合中的偶数,并将结果放到一个新的Stream中Stream<Integer> stream1 = stream.filter(num -> num % 2 == 0);stream1.forEach(System.out::println); }
-
distinct():通过流所生成元素的 hashCode() 和 equals() 去除重复元素
@Test public void main(){List<Integer> list = Arrays.asList(1, 2, 4, 4, 5, 6, 6, 8, 9);Stream<Integer> stream = list.stream();Stream<Integer> distinct = stream.distinct();distinct.forEach(System.out::print); }
-
2、切片
-
limit(long maxSize):截断流,使其元素不超过给定数量
@Test public void main(){List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);Stream<Integer> stream = list.stream();Stream<Integer> limit = stream.limit(5);limit.forEach(System.out::print); }
-
skip(long n):从第n个位置往后截取,若流中元素不足 n 个,则返回一个空流(与 limit(n) 互补,limit(n)是截取第一个到n,而skip是从n到最后)
@Test public void main(){List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);Stream<Integer> stream = list.stream();Stream<Integer> limit = stream.skip(5);limit.forEach(System.out::print); }
3、映射
-
map(Function f):接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素
@Test public void main(){List<Integer> list = Arrays.asList(1, 2, 3,4,5,6,7,8,9);Stream<Integer> stream1 = list.stream();//将所有元素的值*2Stream<Integer> mapStream = stream1.map(num -> num * 2);mapStream.forEach(System.out::println); }
-
flatMap(Function f):接收一个函数作为参数,将流中的每个值都换成另一个流返回,然后把所有流连接成一个流
@Test public void main(){List<String> list1 = Arrays.asList("java","python","c++","c");//将每个元素从新生成一个stream,并添加testStream<String> stringStream = list1.stream().flatMap(s -> {List<String> strings = Arrays.asList(s,"test");return strings.stream();});stringStream.forEach(System.out::println); }
-
mapToDouble(ToDoubleFunction f):接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 DoubleStream。
-
mapToInt(ToIntFunction f):接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 IntStream
-
mapToLong(ToLongFunction f):接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 LongStream。
4、排序
- sorted():产生一个新流,按自然顺序排序,按Comparable接口
- sorted(Comparator com):产生一个新流,其中按比较器顺序排序,按Comparator自定义排序
@Test
public void main2(){List<Person> list = new ArrayList<>();list.add(new Person("张三","女",22,"学生"));list.add(new Person("李四","女",20,"学生"));list.add(new Person("王五","男",30,"工人"));list.add(new Person("赵六","男",10,"学生"));//按年龄升序排序Stream<Person> sorted = list.stream().sorted(Comparator.comparing(Person::getAge));sorted.forEach(System.out::println);//按年龄降序排序System.out.println("====按年龄降序排序====");Stream<Person> sorted1 = list.stream().sorted(Comparator.comparing(Person::getAge).reversed());sorted1.forEach(System.out::println);List<Integer> list1 = Arrays.asList(5,2,7,9,3);//自然排序Stream<Integer> sorted2 = list1.stream().sorted();sorted2.forEach(System.out::print);System.out.println();Stream<Integer> sorted3 = list1.stream().sorted(Comparator.reverseOrder());sorted3.forEach(System.out::print);}

13.7.3、终止操作
终止操作会从流的流水线生成结果。其结果可以是任何不是流的值,例如:List、Integer,甚至是 void 。流一旦进行了终止操作后,就不能再次使用了,否则会出现 java.lang.IllegalStateException: stream has already been operated upon or closed 这个异常。
1、遍历
Stream中的元素是以Optional类型存在的,支持类似集合的遍历。
-
使用forEach
@Test public void main(){List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);Stream<Integer> stream = list.stream();//直接使用forEachstream.forEach(System.out::println); } -
使用迭代器
@Test public void main(){List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);Stream<Integer> stream = list.stream();Iterator<Integer> iterator = stream.iterator();while (iterator.hasNext()){System.out.println(iterator.next());} }
2、聚合
在Stream中有三个方法:
-
count() :返回流中元素总数
-
max(Comparator c):返回流中最大值
-
min(Comparator c):返回流中最小值
@Test public void main(){List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);Stream<Integer> stream = list.stream();System.out.println("最小值:"+stream.min((o1, o2) -> o1-o2));//必须从新创建stream,因为max、min、count都是终止操作Stream<Integer> stream1 = list.stream();System.out.println("最大值:"+stream1.max((o1, o2) -> o1-o2));Stream<Integer> stream2 = list.stream();System.out.println("元素个数:"+stream2.count()); }
3、匹配查找
-
allMatch(Predicate p):检查是否匹配所有元素
-
anyMatch**(**Predicate p) :检查是否至少匹配一个元素
-
noneMatch(Predicate p):检查是否没有匹配所有元素
@Test public void main(){List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);Stream<Integer> stream1 = list.stream();System.out.println("stream中的元素是否都>5:"+stream1.allMatch(x -> x > 5));Stream<Integer> stream2 = list.stream();System.out.println("stream中的元素是否至少有一个>5:"+stream2.anyMatch(x -> x > 5));Stream<Integer> stream3 = list.stream();System.out.println("stream中的元素是否都不>5:"+stream3.noneMatch(x -> x > 5)); }
-
findFirst():返回第一个元素
-
findAny(): 返回当前流中的任意元素(适用于并行流),如果使用串行顺序流的话,它一般返回的就是第一个元素(建议多搞点数据,多运行几次,才能出现差别)
@Test public void main(){List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);Stream<Integer> stream1 = list.stream();System.out.println("第一个元素是:"+stream1.findFirst());//创建并行流Stream<Integer> parallelStream1 = list.parallelStream();Stream<Integer> parallelStream2 = list.parallelStream();Stream<Integer> parallelStream3 = list.parallelStream();Stream<Integer> parallelStream4 = list.parallelStream();Stream<Integer> parallelStream5 = list.parallelStream();Stream<Integer> parallelStream6 = list.parallelStream();Stream<Integer> parallelStream7 = list.parallelStream();Stream<Integer> parallelStream8 = list.parallelStream();System.out.println("返回一个任意元素:"+parallelStream1.findAny());System.out.println("返回一个任意元素:"+parallelStream2.findAny());System.out.println("返回一个任意元素:"+parallelStream3.findAny());System.out.println("返回一个任意元素:"+parallelStream4.findAny());System.out.println("返回一个任意元素:"+parallelStream5.findAny());System.out.println("返回一个任意元素:"+parallelStream6.findAny());System.out.println("返回一个任意元素:"+parallelStream7.findAny());System.out.println("返回一个任意元素:"+parallelStream8.findAny()); }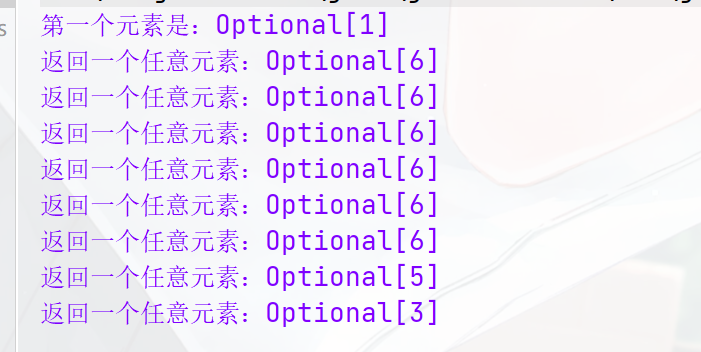
4、归约
归约,也称缩减,是把一个流缩减成一个值,能实现对集合求和、求乘积和求最值操作。
- reduce(T iden, BinaryOperator b):可以将流中元素反复结合起来,得到一个值。返回 T。
- reduce(BinaryOperator b):可以将流中元素反复结合起来得到一个值。返回 Optional
map 和 reduce 的连接通常称为 map-reduce 模式,因Google 用它来进行网络搜索而出名。
@Test
public void main(){List<Integer> list1 = Arrays.asList(1,2,3,4,5,6);//方式1:使用reduce(BinaryOperator b) ,返回值为Optional类//方式2:使用reduce(T iden, BinaryOperator b),返回值和T相关System.out.println("求和方式1:"+list1.stream().reduce(Integer::sum));System.out.println("求和方式2:"+list1.stream().reduce(0,Integer::sum));System.out.println("求乘积1:"+list1.stream().reduce((num1,num2) -> num1*num2));System.out.println("求乘积2:"+list1.stream().reduce(1,(num1,num2) -> num1*num2));System.out.println("求最大值1:"+list1.stream().reduce(Integer::max));System.out.println("求最大值2:"+list1.stream().reduce(0,Integer::max));System.out.println("求最小值:"+list1.stream().reduce(Integer::min));System.out.println("求最小值:"+list1.stream().reduce(10,Integer::min));
}

5、收集
collect收集,是内容最繁多、功能最丰富的部分。它是把一个流收集起来,最终可以是收集成一个值也可以收集成一个新的集合。collect主要依赖 java.util.stream.Collectors 类内置的静态方法。
collect(Collector c):将流转换为其他形式。接收一个 Collector接口的实现,用于给Stream中元素做汇总的方法
Collector 接口中方法的实现决定了如何对流执行收集的操作, Collectors 实用类提供了很多静态方法,可以方便地创建常见收集器实例,具体方法与实例如下
归集
归集:流是不存储数据,所以在流中的数据完成处理后,需要将流中的数据重新归集到新的集合里。
-
list.stream().collect(Collectors.toList()):把流中元素收集到List
可简写为:list.stream().toList()
-
list.stream().collect(Collectors.toSet()):把流中元素收集到Set
-
list.stream().collect(Collectors.toCollection(ArrayList::new)):把流中元素收集到创建的集合
@Test public void main(){List<Integer> list1 = Arrays.asList(1,2,3,4,5,6,6);//toListSystem.out.println("======toList方法======");List<Integer> toList = list1.stream().filter(num -> num % 2 == 0).toList();toList.forEach(System.out::print);System.out.println();//toSetSystem.out.println("======toSet方法======");Set<Integer> set = list1.stream().filter(num -> num%2==0).collect(Collectors.toSet());set.forEach(System.out::print);System.out.println();//toCollectionSystem.out.println("======toCollection方法======");ArrayList<Integer> arrayList = list1.stream().filter(num -> num % 2 == 0).collect(Collectors.toCollection(ArrayList::new));arrayList.forEach(System.out::print); }
-
list.stream().collect(Collectors.toMap()):把流中元素收集到Map
@Test public void main(){List<Person> list = new ArrayList<>();list.add(new Person("张三",20));list.add(new Person("李四",30));Map<String, Person> map = list.stream().collect(Collectors.toMap(Person::getName, p -> p));map.forEach((s, person) -> System.out.println(s+":"+person.toString())); }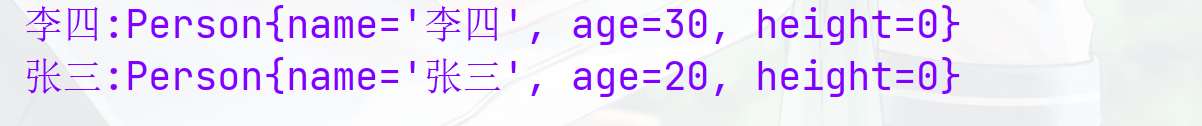
统计
-
Long counting() :计算流中元素的个数(可直接用count)
-
平均值
- Double averagingInt():计算流中元素Integer属性的平均值(符合基本数据类型转换的规则)
- Double averagingLong():计算流中元素Long属性的平均值(符合基本数据类型转换的规则)
- Double averagingDouble():计算流中元素Double属性的平均值(符合基本数据类型转换的规则)
-
最值
- Optional maxBy():根据比较器选择最大值
- Optional minBy():根据比较器选择最小值
-
求和
- Integer summingInt():对流中元素的整数属性求和
- summingLong:对流中元素的Long属性求和
- summingDouble对流中元素的doublt属性求和
-
统计以上所有信息(个数、平均值、最值、和)
- IntSummaryStatistics summarizingInt():收集流中Integer属性的统计值
- summarizingLong
- summarizingDouble
@Test public void main(){List<Person> list = new ArrayList<>();list.add(new Person("张三",22));list.add(new Person("李四",20));list.add(new Person("王五",30));list.add(new Person("赵六",10));Long counting = list.stream().filter(person -> person.getAge() > 20).collect(Collectors.counting());System.out.println("年龄大于20的个数:"+counting);Double averagingInt = list.stream().collect(Collectors.averagingInt(Person::getAge));System.out.println("集合中年龄的平均值:"+averagingInt);Double averagingLong = list.stream().collect(Collectors.averagingLong(Person::getAge));System.out.println("集合中年龄的平均值:"+averagingLong);Double averagingDouble = list.stream().collect(Collectors.averagingDouble(Person::getAge));System.out.println("集合中年龄的平均值:"+averagingDouble);Optional<Integer> maxBy = list.stream().map(Person::getAge).collect(Collectors.maxBy(Integer::compare));System.out.println("最大的年龄是:"+maxBy.get());Integer summingInt = list.stream().collect(Collectors.summingInt(Person::getAge));System.out.println("年龄的和是:"+summingInt);IntSummaryStatistics summarizingInt = list.stream().collect(Collectors.summarizingInt(Person::getAge));System.out.println("根据年龄求以上信息:"+summarizingInt); }
分组
分组:将集合分为多个Map
- Map<K, List> groupingBy():根据某属性值对流分组
- Map<Boolean, List> partitioningBy():根据true或false进行分组
@Test
public void main(){List<Person> list = new ArrayList<>();list.add(new Person("张三","女",22,"学生"));list.add(new Person("李四","女",20,"学生"));list.add(new Person("王五","男",30,"工人"));list.add(new Person("赵六","男",10,"学生"));//按性别进行分组System.out.println("===按性别进行分组分组===");Map<String, List<Person>> mapByGender = list.stream().collect(Collectors.groupingBy(Person::getGender));mapByGender.forEach((s,person)-> System.out.println(s+":"+person.toString()));//按年龄是否>=20岁System.out.println("===按年龄是否>=20岁分组===");Map<Boolean, List<Person>> mapByAge = list.stream().collect(Collectors.partitioningBy(person -> person.getAge() >= 20));mapByAge.forEach((s,person)-> System.out.println(s+":"+person.toString()));//按年龄职业和性别分组System.out.println("===按职业和性别分组===");Map<String, Map<String, List<Person>>> mapByAgeAndGender = list.stream().collect(Collectors.groupingBy(Person::getGender, Collectors.groupingBy(Person::getProfession)));mapByAgeAndGender.forEach((s,person)-> System.out.println(s+":"+person.toString()));
}

字符串拼接
String joining(“连接符”) :连接流中每个字符串
@Test
public void main2(){List<Person> list = new ArrayList<>();list.add(new Person("张三","女",22,"学生"));list.add(new Person("李四","女",20,"学生"));list.add(new Person("王五","男",30,"工人"));list.add(new Person("赵六","男",10,"学生"));//不带连接符号String collect1 = list.stream().map(Person::getName).collect(Collectors.joining());System.out.println(collect1);//带连接符号String collect2 = list.stream().map(Person::getName).collect(Collectors.joining(","));System.out.println(collect2);Stream<String> stream = Stream.of("Java","Python","C++");String collect = stream.collect(Collectors.joining(","));System.out.println(collect);
}

归约
reducing:从一个作为累加器的初始值开始,利用BinaryOperator与流中元素逐个结合,从而归约成单个值,相比于stream 本身的 reduce 方法,增加了对自定义归约的支持

@Test
public void main2(){List<Person> list = new ArrayList<>();list.add(new Person("张三","女",22,"学生"));list.add(new Person("李四","女",20,"学生"));list.add(new Person("王五","男",30,"工人"));list.add(new Person("赵六","男",10,"学生"));//分别求出男女里最大的年龄是多少Map<String, Optional<Person>> collect = list.stream().collect(Collectors.groupingBy(Person::getGender, Collectors.reducing(BinaryOperator.maxBy(Comparator.comparingInt(Person::getAge)))));collect.forEach((s,person)-> System.out.println(s+":"+person.toString()));
}
